
John Brusk, VP of Data Science
When it comes to enterprise spend management, Emburse knows companies deal with a massive amount of financial documents — like invoices, purchase orders, receipts, and travel itineraries and folios. Understanding and processing these documents manually is time-consuming, error-prone, and costly. Large Language Models (LLMs) can transform this process by automating the extraction and interpretation of key information from such documents.
LLMs are advanced artificial intelligence (AI) systems designed to understand, generate, and manipulate human language at a level of sophistication previously unattainable. These models are trained on vast amounts of text data and can perform a wide array of language-related tasks, such as answering questions, summarizing documents, generating content, and even engaging in human-like conversations.
For companies, LLMs represent a significant leap forward in automating and enhancing processes that rely heavily on language. This includes customer support, content creation, marketing, and more. The ability of LLMs to understand context, intent, and nuance means they can handle tasks that traditionally required human intervention, leading to improved efficiency, reduced costs, and enhanced customer experiences. In essence, LLMs can help companies scale their operations and unlock new opportunities by making complex language-based processes faster and more accurate.
At Emburse, we have leveraged and integrated this technology to deliver important expense automation features such as document classification and extraction of information to enable hands free processing such as merchants, locations, dates, taxes and spend amounts. Obtaining high accuracy (>95%) and reliability across tens of thousands of document formats and sources has traditionally required major resources and commitment to manually labeling thousands of documents in order to train a model to predict the same labeled values from new documents. The amount of effort to achieve high accuracy for a given set of values is difficult to predict and can make time to feature delivery unsustainable. Large Language Models (LLMs) have shown impressive capabilities in this domain, providing a high level of accuracy out of the box. While using LLMs for document understanding can sometimes feel like using a sledgehammer to crack a nut, there are specific scenarios where LLMs act as powerful accelerators, particularly when dealing with new values and concepts lacking quality data and well curated labels.
The Challenge of New Values and Concepts
When an Emburse customer, such as a large fintech or legal enterprise, is aiming to extract new information from documents, like the traveler name from hotel folios, the primary challenge is often the absence of quality labeled data. In this case, we now leverage an LLM deployed on our enterprise platform to identify and extract this new information from the outset. This immediate capability ensures that the company can maintain operational efficiency while generating large amounts of high quality labeled data for the development of more refined solutions.
One such solution is named entity recognition (NER) and the machine learning approaches to perform it, such as the use of bidirectional encoder representations from transformers (BERT), which rely heavily on large datasets of labeled examples to achieve high accuracy.
This dual approach—utilizing LLMs for initial deployment and data labeling—maximizes scalability and minimizes costs. Once a sufficient amount of high-quality labeled data is available, more efficient models can take over. These models require fewer resources to operate, reducing ongoing costs and improving scalability for long-term use.
Practical Implementations
Organizations most likely to be successful in leveraging LLMs and generative AI will be those that deploy their applications as pipelines that comprise several approaches used together to maximize accuracy and cost. Emburse is leading the way in document intelligence innovation and research and has demonstrated the effectiveness of this approach. By employing LLMs for initial data labeling, Embuse has managed to scale its operations efficiently while maintaining high accuracy. This hybrid strategy ensures that new solutions can be deployed swiftly, even in the absence of pre-existing labeled data.
Emburse Document Intelligence Pipeline
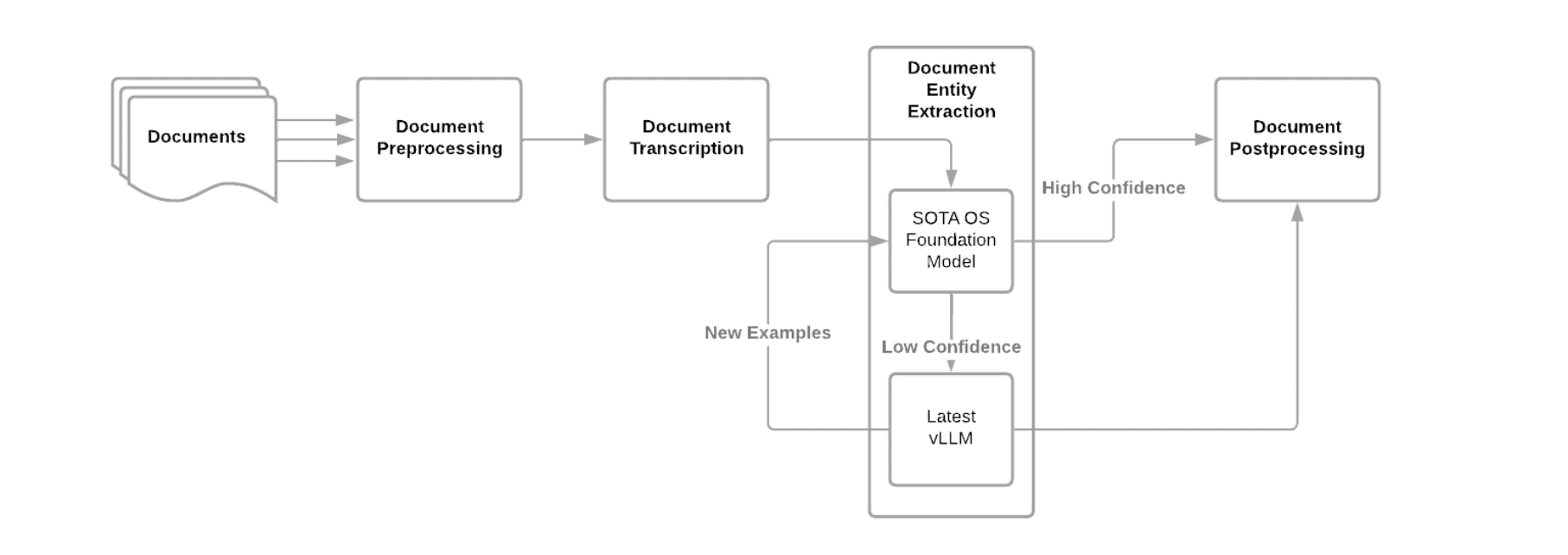
The Emburse document intelligence pipeline combines the use of computer vision models for document preprocessing, open source OCR for transcribing raw text and LLMs to analyze the text for entity extraction. A platform based approach enabling the use of the latest state of the art (SOTA) open source (OS) foundation model available, fine-tuned on Emburse labeled documents is demonstrating significantly better performance than any of the OCR solutions leveraged in the past.
A critical part of the document intelligence pipeline, as mentioned previously, is the ability to leverage the constantly emerging availability of what I would call “very large language models” (vLLM), or commercially available and hosted LLMs that comprise more than 100 billion parameters in order to both provide quality training examples for open source LLM transfer learning, but also such an implementation can mitigate potential low confidence responses from the OS implementation, but routing those to the vLLM for processing. The latest high performing SOTA OS foundation models have less than 10 billion parameters, making it more feasible for hosting and scaling, but require examples drawn from a statistically similar domain in order to perform well. In cases where examples do not currently generalize well to the existing population, the vLLM can be called to fulfill the task. This minimizes reliance on the vLLM but enables taking advantage of its power when needed.
It should be noted that although feasible to deploy an OS model of 10 billion parameters, ideally a quantized version of the model is deployed to production. Model quantization is a technique used to reduce LLMs by reducing the precision of their weights, allowing execution on less powerful hardware with minimal impact to accuracy. A future blog post by our lead MLDevOps Engineer will dig more into this process and our latest findings along with additional details on navigating approaches to open source LLM deployment for enterprise applications.
Conclusion
We’re building leading-edge innovations in AI and machine learning here at Emburse that solve real customer problems. LLMs play a crucial role as accelerators in the fintech industry, especially when dealing with new entities lacking labeled data. By providing immediate production capabilities and generating high-quality labeled datasets, LLMs enable organizations to quickly deploy a variety of solutions to power intelligent information retrieval, summarization and classification across many use cases and disciplines, from auto-populating forms like expense reports to providing high quality answers to difficult questions about compliance, spend optimization and operational efficiency. The hybrid strategy of deploying performant software quickly while curating high quality data with LLMs balances the need for accelerated feature innovation delivery to the customer with the long-term benefits of using the curated data to train more efficient and scalable task specific machine learning applications with comparable accuracy, with significantly reduced cost and enhanced scalability.